Rust 进阶学习笔记(四):宏
Rust编译过程和宏,声明宏,过程宏:派生宏、属性宏、函数宏
本文属于我的 Rust 学习笔记 系列,您现在看到的这段话是本系列的固定起始语。
Rust 入门学习笔记以实际例子为主,讲解部分不是从零开始的,所以不建议纯萌新观看,读者最好拥有任意一种面向对象语言的基础,然后自己多多少少看过 Rust 的基本语法,刷过一点 rustlings。
Rust 进阶学习笔记以及实战的来源则五花八门,将会标注在下一行⬇️。
本节出处:Databend 分享
这一节写的比较粗糙,等我学完 Workshop 后会重新整理的。不过宏其实没必要看的这么细,很少能够用到这么原理层面的东西。
宏
之前已经遇到过很多带有!的东西,比如println!、vec!等,以及一些#[derive]。这些东西就叫做宏。
宏(Macro)指的是 Rust 中一系列的功能:使用macro_rules!的声明宏(declarative macro),和三种过程宏(procedural macro):派生宏、属性宏、函数宏。
所谓宏,其实就是一种通过代码生成代码的方式,即“元编程(metaprogramming)”。宏以展开的方式来生成比宏本身的代码更多的代码。
和函数相比,宏不需要声明参数的数量和类型,并且会在编译器解析代码前展开,而非运行时调用。因此,宏的定义更复杂,更难维护。
Rust 编译过程
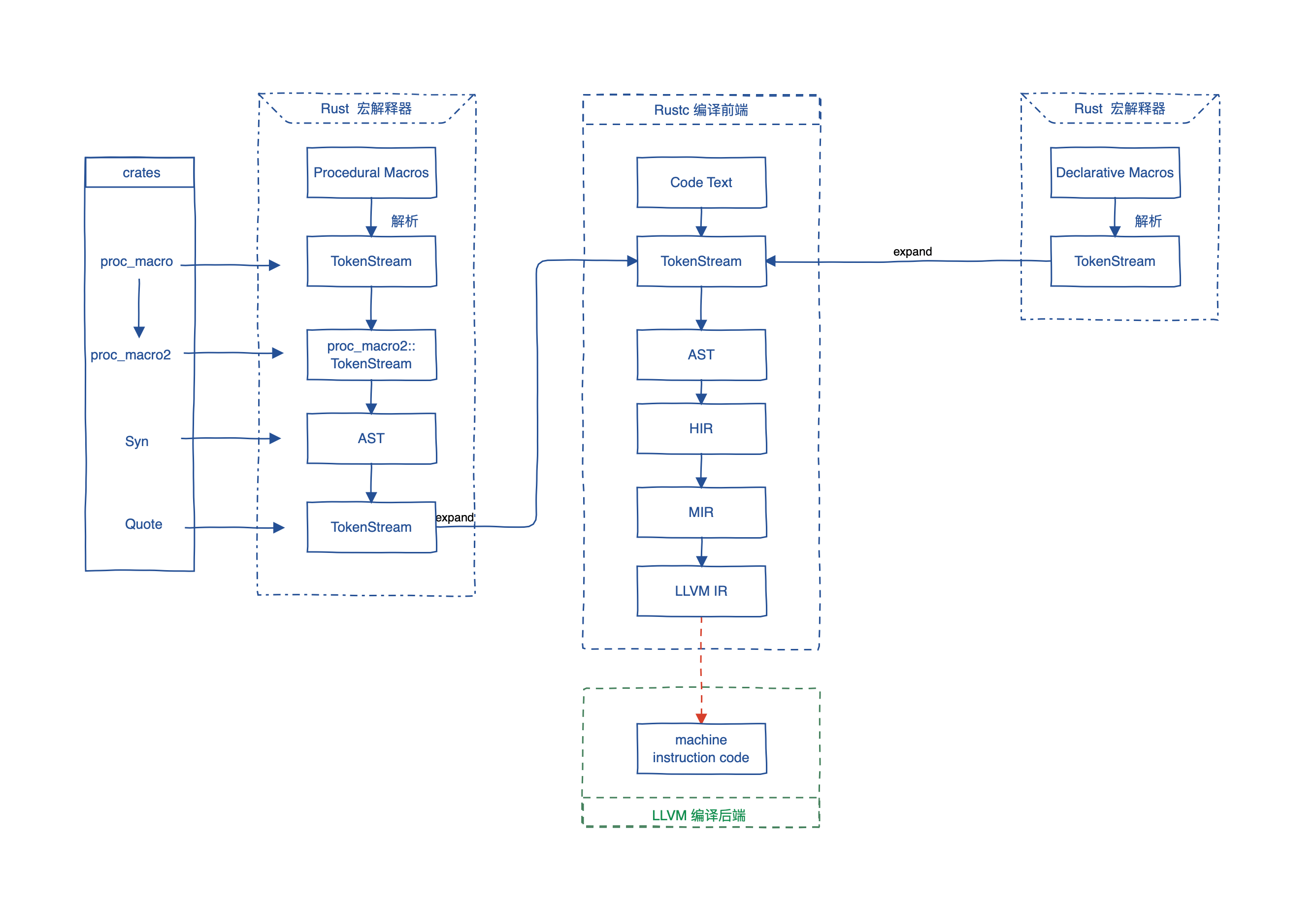
Rust 整体编译过程就是图中间“编译前端”Rustc到“编译后端”LLVM这一部分。我们的文本代码会经过分词形成词条流(即词法分析),这一过程中就会解析宏。词法分析后会形成一个抽象语法树(AST),然后进行语义分析。HIR 是 AST 简化后的降级,进行语法糖的“脱糖”,做类型推断。MIR 是进一步降级形成中级中间语言,会进行借用检查。最后生成一个 LLVM 的中间语言。
可以从 Rust 官方 Playground 左上角的编译选项中清晰看到整个过程每一步生成的代码是什么样的。
宏的解析器是主线之外单独的,并且声明宏和过程宏也是分开的。声明宏实际上是一个替换,替换会发生在声明层面,然后混入普通的 token stream 里面,这个过程可以理解为和正则表达式匹配是一样的,没有计算和语义分析。过程宏的工作机制也类似,但是其出入参都是 token stream,在 token stream 上通过第三方库 Syn 构造了一个自己的 AST,其目的是方便根据类型信息进行一些计算,最后会转换为普通的 token stream。
声明宏
声明宏(declarative macros)允许编写一些类似match表达式的控制结构,将一个值和包含相关代码的模式进行比较,一旦匹配成功,每个模式的相关代码会替换传递给宏的代码。所有这一切都发生于编译时。rust 会通过std::prelude自动引入宏,无需手动声明。。
举个例子,假设我们想通过宏创建一个数组,就可以这么写:
let v: = vec!;
vec!创建的动态数组支持任何元素类型,也并没有限制数组的长度。
来看!vec的简化版本定义,这里之所以是简化版是因为省略了预分配空间的代码。
可以看到,!vec的定义看起来就是只有一个分支、一个模式的match表达式。
定义方式
接下来就来解析这段代码。
#[macro_export]注解表明只要导入了定义这个宏的crate,该宏就应该是可用的。如果没有该注解,这个宏不能被引入作用域。
接着使用macro_rules!和宏名称开始宏定义,且所定义的宏并不带感叹号。名字后跟大括号表示宏定义体,在该例中宏名称是vec。
vec!宏的结构和match表达式的结构类似。此处有一个分支模式( $( $x:expr ),* ),后跟=>以及和模式相关的代码块。如果模式匹配,该相关代码块将被展开。鉴于这个宏只有一个模式,那就只有一个有效匹配方式,其他任何不匹配这个模式都会导致错误。更复杂的宏会有不止一个分支。
模式解析
首先,我们使用圆括号()将整个宏模式包裹其中。紧随其后的是$(),与$后的括号中的模式相匹配的值(传入的 Rust 源代码)会被捕获,然后用于代码替换。在本例中,模式$x:expr会匹配任何 Rust 表达式,并把它叫做$x。$()后面的,表示所匹配的代码使用逗号分隔符分割,*表示*之前的模式,即$()中的部分将会被匹配任意次(零到无限次,类似正则表达式)。
我们创建的数组中,这个模式就是被匹配并循环了 3 次。
注意这种写法,数组最后一个元素后不能再跟
,。想要能够匹配这种可有可无的逗号,需要这样写:
=> ;
接下来,我们再来看看与模式相关联、在=>之后的代码。$()中的部分将根据模式匹配的次数生成对应的代码,也就是说有几个元素就执行几次,本例中就是循环执行了 3 次temp_vec.push($x);。当调用vec![1, 2, 3]时,下面这段生成的代码将替代传入的源代码:
至此,我们定义了一个可以接受任意类型和数量的参数声明宏,并且理解了其语法的含义。
扩展
The Little Book of Rust Macros
过程宏
过程宏的本质是编译过程中的一个过滤器或中间件,它接收一段用户编写的源代码,返回给编译器一段经过修改后的代码。
过程宏必须定义在一个单独的 crate 中。这一点需要回到编译过程来理解:Rust 的最小编译单元就是 crate,过程宏是在编译一个 crate 之前对 crate 的代码进行加工的一段程序,然而它本身也需要编译后才能执行。如果定义和使用过程宏的代码写在一个 crate 中,编译过程就死锁了。
得益于此,在一个项目中定义过程宏的代码往往会位于一个单独的 crate 中,我们很容易找到并学习。
定义过程宏
直接来看几个例子。
首先需要在宏定义所在的包,比如my_macro里的Cargo.toml中定义proc-macro=true,然后添加三个依赖包。这里的三个包是属性宏用到的,定义其他宏可能并不需要全部的三个包。过程宏编译器依赖这三个包来进行转换。Rust 有很多内置的功能都是像这样,不属于标准库 std,而是通过官方提供的外部 crate 来实现。
[]
= "my_macro"
= "0.1.0"
= "2024"
[]
=true
[]
= "1.0.95"
= "1"
= { = "2.0", = ["full"] }
然后在主项目的Cargo.toml中使用dependencies或workspace引入过程宏的包。这里就先用 dependencies。
[]
= "macro_test"
= "0.1.0"
= "2024"
[]
= { = "my_macro"}
接下来定义一个简单的过程宏。
use TokenStream;
// proc_macro_attribute 表示定义的是一个属性宏
// 派生宏是 #[proc_macro_derive],如果是函数宏,则是 #[proc_macro]
// 只有在 Cargo.toml 中设置了 proc-macro=true 的 crate 能够引入这一标注
这段过程宏定义的代码已经写完了,可以看到作为演示,这个宏把输入原样输出,实际上什么都没改变。
然后我们尝试进行调用。
// 过程宏所在的包名叫 my_macro
// test 就是所谓“属性”,即宏定义中的 attr
上文定义的这个宏不会改变代码,只在编译时打印了一些内容。如要在运行时改变函数,可考虑下面这种宏:
下面会再用一个例子讲一下这些语法又是什么意思。
这是 deno flask test 的 0.1.0 版本,源码。这个宏内容比较简单,适合用于学习。请看下面的注释。
// 这个宏创建了一个“不稳定测试”的包装器,会将一个普通函数转换为一个可以自动重试的测试函数,最多重试 3 次。
extern crate proc_macro;
extern crate syn;
use TokenStream;
use quote;
理解过程宏
上一节中的例子里,我们在编译时打印了属性宏内的 attr 和 input 的内容。打印结果如下:
attr: TokenStream [
Literal {
kind: Str,
symbol: "test",
suffix: None,
span: #0 bytes(54..60),
},
]
input: TokenStream [
Ident {
ident: "fn",
span: #0 bytes(63..65),
},
Ident {
ident: "add",
span: #0 bytes(66..69),
},
Group {
delimiter: Parenthesis,
stream: TokenStream [
Ident {
ident: "a",
span: #0 bytes(70..71),
},
Punct {
ch: ':',
spacing: Alone,
span: #0 bytes(71..72),
},
Ident {
ident: "i32",
span: #0 bytes(72..75),
},
Punct {
ch: ',',
spacing: Alone,
span: #0 bytes(75..76),
},
Ident {
ident: "b",
span: #0 bytes(77..78),
},
Punct {
ch: ':',
spacing: Alone,
span: #0 bytes(78..79),
},
Ident {
ident: "i32",
span: #0 bytes(79..82),
},
],
span: #0 bytes(69..83),
},
Punct {
ch: '-',
spacing: Joint,
span: #0 bytes(84..85),
},
Punct {
ch: '>',
spacing: Alone,
span: #0 bytes(85..86),
},
Ident {
ident: "i32",
span: #0 bytes(87..90),
},
Group {
delimiter: Brace,
stream: TokenStream [
Ident {
ident: "a",
span: #0 bytes(97..98),
},
Punct {
ch: '+',
spacing: Alone,
span: #0 bytes(99..100),
},
Ident {
ident: "b",
span: #0 bytes(101..102),
},
],
span: #0 bytes(91..104),
},
]
从上面打印的信息中,能够看出以下信息:
- TokenStream 以树形结构的数据组织,表达了⽤户源代码中各个语⾔元素的类型以及相互之间的关系。
- 每个语⾔元素都有⼀个 span 属性,记录了这个元素在⽤户源代码中的位置。
- 不同类型的节点,有各⾃独有的属性。可以去 syn 包里查看各个类型的注释。
- Ident 类型表示的是⼀个标识符,变量名、函数名等等都是标识符。
- TokenStream ⾥⾯的信息,是没有语义信息的,⽐如在上⾯的例⼦中,路径表达式中的双冒号::被拆分为两个独⽴的冒号对待,TokenStream 并没有把它们识别为路径表达式,同样,它也不区分这个冒号是出现在⼀个引⽤路径中,还是⽤来表示数据类型。
- 针对 attr 属性⽽⾔,其中不包括宏⾃⼰的名称的标识符,它包含的仅仅是传递给这个过程宏的参数的信息。
总结:所谓的过程宏,就是我们可以⾃⼰修改上⾯的 item 变量中的值,从⽽等价 于加⼯原始输⼊代码,最后将加⼯后的代码返回给编译器即可。
补充学习资料:过程宏包作者提供的 Workshop
三种过程宏
本节说一下三种过程宏的联系和区别。
开发过程宏时,可以使用 cargo-expand 展开一个宏,方便阅读和调试。
# 安装方法
# 使用方法
派生宏
假设我们有一个特质 HelloMacro,现在有两种方式让用户使用它:
- 为每个类型手动实现该特质,就像之前特质章节所做的
- 使用过程宏来统一实现该特质,这样用户只需要对类型进行标记即可:
#[derive(HelloMacro)]
以上两种方式并没有孰优孰劣,主要在于不同的类型是否可以使用同样的默认特质实现,如果可以,那过程宏的方式可以帮我们减少很多代码实现。不过为了实现这种功能,我们还需要创建相应的过程宏才行。
extern crate proc_macro;
use TokenStream;
use quote;
use syn;
use DeriveInput;
可以看到,派生宏只有一个参数,是没有第二各参数 attr 的。这是肯定的,因为 attr 就是属性宏的“属性”。
// 使用示例
// 假设 HelloMacro 特质在某处定义
// 用户代码
;
总结:派生宏自动为类型实现特质,避免用户手动为每种类型编写重复代码。
派生宏只能用在结构体/枚举/联合体(union,一种共享存储的结构体)上,多数时候是用在结构体上。
属性宏
过程宏这节的第一个例子就是属性宏,这里再对比一下。
和派生宏相比,属性宏允许我们定义自己的属性,并且可以用于包括函数在内的多种类型。
假设我们在开发一个 web 框架,当用户通过 HTTP GET 请求访问/根路径时,使用 index 函数为其提供服务:
这里的 #[route] 属性就是一个过程宏,它的定义函数大概如下:
与 derive 宏不同,类属性宏的定义函数有两个参数:
- 第一个参数时用于说明属性包含的内容,即括号内的
Get, "/"部分 - 第二个是属性所标注的类型项,在这里是
fn index() {...}。注意,函数体也被包含其中。
除此之外,类属性宏跟 derive 宏的工作方式并无区别:创建一个包,类型是 proc-macro,接着实现一个函数用于生成想要的代码。
函数宏
类函数宏可以让我们定义像函数那样调用的宏,和声明宏的区别在于,函数宏并不是模式匹配的形式,而是过程宏的形式。过程宏使用起来更加灵活。
假设我们需要对 SQL 语句进行解析并检查其正确性,就可以定义这样一个宏:
use TokenStream;
use quote;
use ;
而使用形式则类似于函数调用:
use sql;
总结
虽然 Rust 中的宏很强大,但是它并不应该成为我们的常规武器,原因是它会影响 Rust 代码的可读性和可维护性。
扩展阅读:Rust 宏小册
📝 系列导航